
At least not always.
Background
In common network literature, you will typically find claims that the IPv4 header and the TCP header are both typically 20 bytes long, which leads to a 40-byte overhead of typical Internet-TCP-payloads. For example, the Cloudflare learning center states:
TCP headers are almost always 20 bytes long.
https://www.cloudflare.com/learning/network-layer/what-is-mss/
If you google “TCP header size” you get also 20 bytes. Wikipedia is a bit more conservative, stating that the minimum size is 20 bytes. RFC6691 calls the 20-byte TCP header the “fixed TCP header”.
All of these statements, with perhaps Cloudflare being the exception, are correct. However, in various contexts this can be misleading: Because in practice, the size of the TCP header is not always 20 bytes. And in fact, I argue that it’s not even that common for the TCP header to be 20 bytes.
TCP supports options
If we have a closer look at the TCP format, we can see that there is a variable-sized option field that follows the “fixed” part of the header:

The fixed part of the header (source port, destination port, sequence number, ack number, offset+flags, window size, checksum, urgent pointer) is indeed 20 bytes, so that’s where the TCP-is-20-bytes assumption comes from. The “options” are all, well, optional, so it’s easy to assume that in a general networking setup, no options are used. Right? Well, let’s see which options are there:
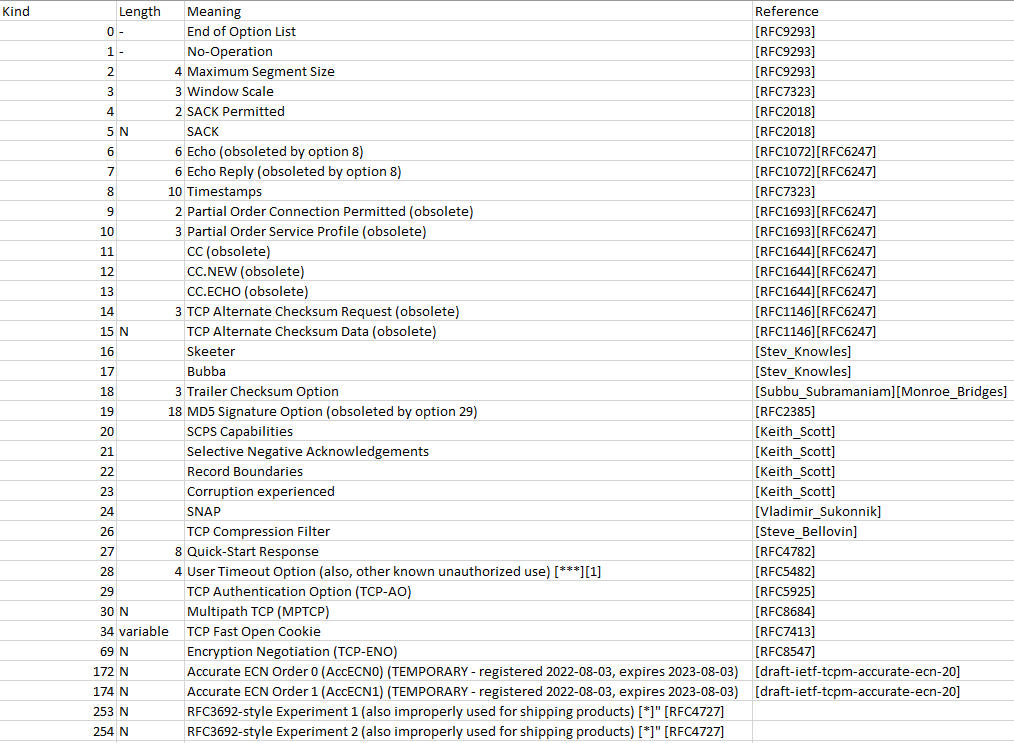
Currently, there are 36 assigned option kinds (including end-of-option and no-operation). There are also various reserved but unused options.
Many of these options are however either outdated, obsolete, deprecated, experimental, or not commonly supported. Also, some options (like maximum segment size, window scaling or SACK permitted) are commonly used, but are only effective during the TCP handshake: That is, when a new TCP connection is established they are present for a short time, but disappear right after the handshake. Hence, the statement that “TCP headers have usually 20 bytes” would be correct, except for the handshake. But the handshake is only a fraction of all TCP packets send, so the statement would still apply.
But there is another option
I’m talking about Option ID 8 “timestamps” in the above screenshot. TCP timestamps are a feature from 1992, originally defined in RFC1323 (updated in RFC7323) as “Round-Trip Time Measurement”.
This option is special for two reasons:
- It is also present after the TCP handshake, as it is applied to each data packet (if the option is active)
- It’s been enabled in Linux by default since like forever (< Linux 2.6) [1][2]
The purpose of this option varies: It can be used for improved round trip time measurments (which is important for TCP, as it controls the send speed and hence the performance) as well as for various tweaks like “Protection Against Wrapped Sequence Numbers” (see the above RFCs).
It’s important to note that recent Windows versions have this option disabled by default, while it’s commonly turned on with anything Linux-based. A paper claims that in 2017, the timestamp option was used in 41.8% of connections monitored at a University.
In my book, 41.8% overall usage is significant: Definetly more than “almost never”. Whenever that option is in use, TCP headers increase by typically 12 bytes (the option uses 10 bytes including kind + length, two additional bytes are usually needed for end-of-option and padding).
Why is this important?
First of all, I think it’s interesting because this is rarely mentioned in literature. The TCP timestamp option is so often used, yet everyone seems to believe that options are the exception, and not the default. This can create some misconceptions, especially when it comes to values that rely on the header size:
Maximum Segment Size (MSS)
Almost all networks transporting IP-packets have a maximum size they can support. For example, Ethernet is commonly limited to 1500 bytes (without jumbo frames). 1500 bytes is also a typical internet-wide maximum transmission unit (MTU), but some networks have a smaller MTU.
However, there isn’t really a way for networks to explicitly state their MTU: The sender must assume some value. However, the TCP protocol has an option (which is also listed above) – the Maximum Segment Size (MSS).
MSS is basically the same as MTU, but with one important difference: MSS only counts the payload bytes of a TCP packet, not the headers. That’s not really helpful in practice: Hosts typically use the MSS extension to inform hosts of their MTU. But in order to do that, they must know the size of the TCP header and the IP header. Now, with them being variable, what are hosts supposed to do?
This question actually warranted an entire (altough short) RFC: RFC6691. It states:
When calculating the value to put in the TCP MSS option, the MTU value SHOULD be decreased by only the size of the fixed IP and TCP headers and SHOULD NOT be decreased to account for any possible IP or TCP options; conversely, the sender MUST reduce the TCP data length to account for any IP or TCP options that it is including in the packets that it sends [...]https://www.rfc-editor.org/rfc/rfc6691.html
Which basically means “when a host sends MSS, assume that MTU is MSS + 40 bytes”. This isn’t entirely obvious, at least it wasn’t to me.
Seeing this in action
If the above was all too theoretical for you, I have a tool where you can see this in action:
https://segmentist.germancoding.com/
This is a small tool I wrote to see whether hosts actually respect the MSS header, if set by service. The short answer to that question is: Yes, internet-reachable hosts generally do. However, if you use that tool you will see a typical pattern like this:
The target server appears to respect the Maximum Segment Size (MSS) advertised by us. We requested a MSS of 1000 bytes and we received packets not exceeding 988 bytes. In addition, the packets send by the target never exceeded our (presumed) MTU of 1040 bytes. The largest packet in total, including layer 3 headers, was 1040 bytes.
Output from https://segmentist.germancoding.com/
So, we send a 1000-bytes MSS, but the payload never exceeded 988 bytes. Why does that still make sense? Because of the TCP timestamp option: The sender used TCP timestamps and hence the TCP header was 32 bytes long. Add a 20 bytes IPv4 header and you get 52 bytes overhead. Now, since the MSS is 1000 bytes, the “assumed” MTU as per RFC6691 is 1040 bytes. With an overhead of 52 bytes, the maximum TCP payload possible is 1040 – 52 = 988 bytes.
Thus, everytime you see a host responding with “988” bytes on Segmentist, you know that it uses the TCP timestamp option. Therefore, TCP headers are not 20 bytes long: Sometimes they are 20 bytes, sometimes 32, and sometimes something completly different. This isn’t a rare edge case in any way: Simply try out my tool with various hosts and see how often the TCP timestamp option is used. It’s definetly not “rare”. Hence this post.
What about IPv6?
The above applies in theory to IPv6 as well. However, Segmentist currently does not support IPv6 (due to a code limitation; will hopefully be resolved in the future), sorry. The IPv6 header is also different in size: Its fixed header is 40 bytes, plus possible extension headers.