Recently, it happened to me as well: I ran out of disk space on a “production” system, and all hell broke loose. So here’s the short postmortem:
The trigger was me playing around with server-side LDAP settings. Ironically those were intended to make stuff more stable and prevent outages. The new config was enabled, I verified that the LDAP clients could still logon and everything.
The next day, everything seemed to be fine. That was, until some scripts on one of my machines started behaving a bit erratically. It logged a few unusual errors (such as being unable to write to a file), but everything else seemed normal – no service was down. Eventually stuff started crashing at about the same time when I started investigating the unusual errors.
Analysis quickly pointed to disk trouble: A failing disk perhaps? No, #df -h revealed the problem: /dev/mmcblk0p3 55G 55G 0 100% /. The 64 GB eMMC on my Odroid had completly filled up to 100%. The normal disk usage on that eMMC is at around 20 GiB. So who had eaten around 35 GiB of disk space? Further checks with #du -hs /var/lib/docker/containers appointed the blame to Docker: One of the containers was over 30 GB in size!
How could that happen? Well, remember the LDAP changes? On the machine, the affected container contained a login routine that was trying to login via LDAP. This had ran into a hiccup where the routine failed to login1, logged an error, then tried again. It was doing this on an infinite loop – there was no backoff or retry count/timeout built into it.
The sheer amount of error lines emitted by the routine caused the docker container’s log file (which is in json format by default) to grow huge. And now to the real surprise: The Docker default json logging driver does not have any sort of rotation or size limit build into it! It just fills your disk until eternity. The docker configuration manual has a notice that warns about this behaviour, but honestly who digs so deep in that manual? It’s not like it’s a top-10 page or something. Why the heck is this the default? “For backwards compatibility reasons” – well, then why don’t we change it for new setups only? I think this is a really stupid design decision, but yeah.
So, lessons learned:
On all new docker installs, change /etc/docker/daemon.json to use the local log driver, or json with a size limit configured.
Monitor your disk usage at all times, with alerting if stuff becomes critical.
Implement backoffs for operations that should be retried. Don’t hammer infinite loops when stuff doesn’t work.2
In common network literature, you will typically find claims that the IPv4 header and the TCP header are both typically 20 bytes long, which leads to a 40-byte overhead of typical Internet-TCP-payloads. For example, the Cloudflare learning center states:
All of these statements, with perhaps Cloudflare being the exception, are correct. However, in various contexts this can be misleading: Because in practice, the size of the TCP header is not always 20 bytes. And in fact, I argue that it’s not even that common for the TCP header to be 20 bytes.
TCP supports options
If we have a closer look at the TCP format, we can see that there is a variable-sized option field that follows the “fixed” part of the header:
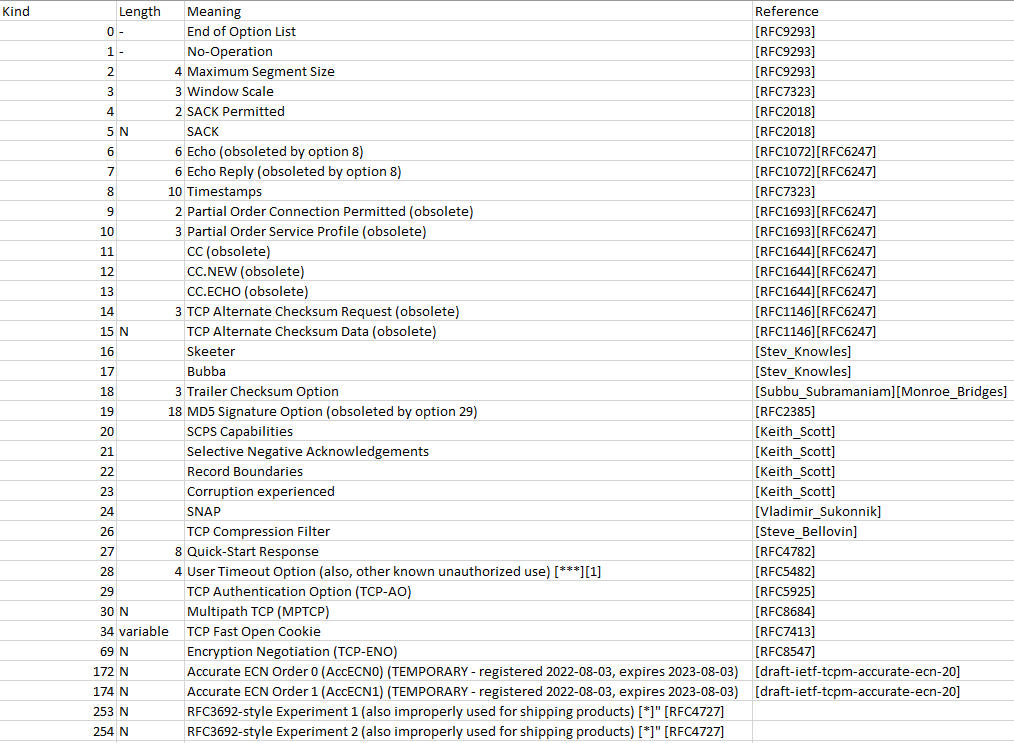
The fixed part of the header (source port, destination port, sequence number, ack number, offset+flags, window size, checksum, urgent pointer) is indeed 20 bytes, so that’s where the TCP-is-20-bytes assumption comes from. The “options” are all, well, optional, so it’s easy to assume that in a general networking setup, no options are used. Right? Well, let’s see which options are there:
Currently, there are 36 assigned option kinds (including end-of-option and no-operation). There are also various reserved but unused options.
Many of these options are however either outdated, obsolete, deprecated, experimental, or not commonly supported. Also, some options (like maximum segment size, window scaling or SACK permitted) are commonly used, but are only effective during the TCP handshake: That is, when a new TCP connection is established they are present for a short time, but disappear right after the handshake. Hence, the statement that “TCP headers have usually 20 bytes” would be correct, except for the handshake. But the handshake is only a fraction of all TCP packets send, so the statement would still apply.
But there is another option
I’m talking about Option ID 8 “timestamps” in the above screenshot. TCP timestamps are a feature from 1992, originally defined in RFC1323 (updated in RFC7323) as “Round-Trip Time Measurement”.
This option is special for two reasons:
It is also present after the TCP handshake, as it is applied to each data packet (if the option is active)
It’s been enabled in Linux by default since like forever (< Linux 2.6) [1][2]
The purpose of this option varies: It can be used for improved round trip time measurments (which is important for TCP, as it controls the send speed and hence the performance) as well as for various tweaks like “Protection Against Wrapped Sequence Numbers” (see the above RFCs).
It’s important to note that recent Windows versions have this option disabled by default, while it’s commonly turned on with anything Linux-based. A paper claims that in 2017, the timestamp option was used in 41.8% of connections monitored at a University.
In my book, 41.8% overall usage is significant: Definetly more than “almost never”. Whenever that option is in use, TCP headers increase by typically 12 bytes (the option uses 10 bytes including kind + length, two additional bytes are usually needed for end-of-option and padding).
Why is this important?
First of all, I think it’s interesting because this is rarely mentioned in literature. The TCP timestamp option is so often used, yet everyone seems to believe that options are the exception, and not the default. This can create some misconceptions, especially when it comes to values that rely on the header size:
Maximum Segment Size (MSS)
Almost all networks transporting IP-packets have a maximum size they can support. For example, Ethernet is commonly limited to 1500 bytes (without jumbo frames). 1500 bytes is also a typical internet-wide maximum transmission unit (MTU), but some networks have a smaller MTU.
However, there isn’t really a way for networks to explicitly state their MTU: The sender must assume some value. However, the TCP protocol has an option (which is also listed above) – the Maximum Segment Size (MSS).
MSS is basically the same as MTU, but with one important difference: MSS only counts the payload bytes of a TCP packet, not the headers. That’s not really helpful in practice: Hosts typically use the MSS extension to inform hosts of their MTU. But in order to do that, they must know the size of the TCP header and the IP header. Now, with them being variable, what are hosts supposed to do?
This question actually warranted an entire (altough short) RFC: RFC6691. It states:
When calculating the value to put in the TCP MSS option, the MTU value SHOULD be decreased by only the size of the fixed IP and TCP headers and SHOULD NOT be decreased to account for any possible IP or TCP options; conversely, the sender MUST reduce the TCP data length to account for any IP or TCP options that it is including in the packets that it sends [...]
https://www.rfc-editor.org/rfc/rfc6691.html
Which basically means “when a host sends MSS, assume that MTU is MSS + 40 bytes”. This isn’t entirely obvious, at least it wasn’t to me.
Seeing this in action
If the above was all too theoretical for you, I have a tool where you can see this in action:
This is a small tool I wrote to see whether hosts actually respect the MSS header, if set by service. The short answer to that question is: Yes, internet-reachable hosts generally do. However, if you use that tool you will see a typical pattern like this:
The target server appears to respect the Maximum Segment Size (MSS) advertised by us. We requested a MSS of 1000 bytes and we received packets not exceeding 988 bytes. In addition, the packets send by the target never exceeded our (presumed) MTU of 1040 bytes. The largest packet in total, including layer 3 headers, was 1040 bytes.
So, we send a 1000-bytes MSS, but the payload never exceeded 988 bytes. Why does that still make sense? Because of the TCP timestamp option: The sender used TCP timestamps and hence the TCP header was 32 bytes long. Add a 20 bytes IPv4 header and you get 52 bytes overhead. Now, since the MSS is 1000 bytes, the “assumed” MTU as per RFC6691 is 1040 bytes. With an overhead of 52 bytes, the maximum TCP payload possible is 1040 – 52 = 988 bytes.
Thus, everytime you see a host responding with “988” bytes on Segmentist, you know that it uses the TCP timestamp option. Therefore, TCP headers are not 20 bytes long: Sometimes they are 20 bytes, sometimes 32, and sometimes something completly different. This isn’t a rare edge case in any way: Simply try out my tool with various hosts and see how often the TCP timestamp option is used. It’s definetly not “rare”. Hence this post.
What about IPv6?
The above applies in theory to IPv6 as well. However, Segmentist currently does not support IPv6 (due to a code limitation; will hopefully be resolved in the future), sorry. The IPv6 header is also different in size: Its fixed header is 40 bytes, plus possible extension headers.
Recently, I have been playing with UEFI secure boot and custom modules. I am one of the lucky people to own one of the discontinued Odroid H2+ models, a small board with decent computing capabilities.
The Odroid features an x86 CPU, so there are no ARM weirdnesses to worry about. However, the default BIOS setting of this board seems to be UEFI Secure Boot off. But what even is Secure Boot?
Secure Boot is a method to prevent Rootkits and other malicious software to execute code during boot. While the system is booting, it is generally less protected. If the operating system has not yet loaded, any protection provided by the OS is not yet working. The earlier something runs in the boot process, the more power it has: It can control all execution after itself.
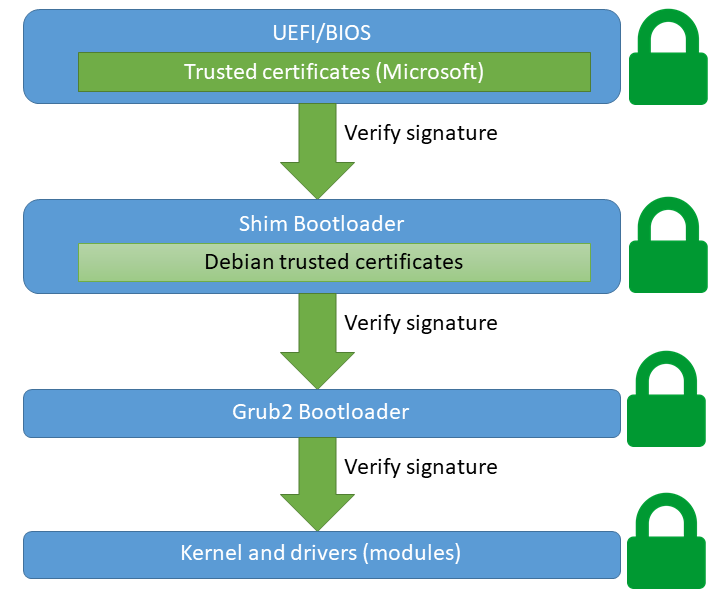
While Secure Boot also has weaknesses and it sometimes debated, it is supposed to alleviate some of these concerns. UEFI Secure Boot ensures that all code part of the boot sequence is authenticated and has not been tampered with.
This graphic means that everything involved during the boot processes must be signed by a trusted certificate. We’re assuming Debian here. By default, most mainboards (UEFI’s) only ship Microsoft’s Root UEFI certificate. Most first-party bootloaders will therefore be signed with Microsoft’s key, to be compatible everywhere.
However, non-Microsoft projects use their own infrastructures and don’t want/can’t have every update signed by Microsoft. Instead, they use their own certificates. My Debian 11 uses two certificates for this, including Debian Secure Boot Signer 2021 and Debian Secure Boot CA. These certificates ensure that non-Microsoft signed code can load. A so-called “shim” bootloader is signed by Microsoft and will load the Debian-specific code and certificates. Therefore only the shim needs to be signed by Microsoft.
Also, in case this was not clear: UEFI Secure Boot requires an UEFI boot. If your OS was installed via the legacy BIOS system (you’re booting legacy), you can’t use UEFI features such as Secure Boot. You will need to migrate to UEFI first, which often involves a difficult bootloader swap or just reinstalling the entire system with UEFI enabled. Modern systems usually come with UEFI on by default.
My Odroid H2+ has two Realtek 8125B 2.5 Gbit network cards onboard. These are damn nice things, multi Gigabit for a cheap price. However, as with all new hardware on Linux, one question is always there: “Does it work with my Linux kernel?”.
If you run an operating system with Linux kernel 5.9 or higher (Debian 11, Ubuntu 20.04+ with HWE kernel…), the answer is yes: It will work out of the box, as the R8169 module/driver shipped with the kernel supports RTL8125B since 5.9.
However, my tests indicated that while the network cards indeed work, throughput wasn’t great: I was getting barely 2 Gigabit/s in an iperf3 test, nothing close to the 2.5 Gbit/s promised by the specification. So I had a look around whether there are better drivers. Indeed it looks like there is:
Realtek indeed seems to ship its own first party driver – it’s even open source and GPL licensed, but not included in the official Linux kernel source tree. Still, I tried out this project, which builds a nice DKMS kernel module out of the Realtek driver. DKMS is “Dynamic Kernel Module Support”, a framework to generate and load kernel modules easily. It takes care of things like recompiling your modules when you upgrade your kernel or switch configurations.
After installing the DKMS module, we had the new Realtek driver (module) available. However, even after a reboot it wasn’t active: My kernel seemed to prefer its inbuild R8169 module, so I had to explicitly block that (using the method described in the readme). After this, my kernel was forced to load my new Realtek R8125B module.
That was a great success! The new module achieved a steady 2.5 Gbit/s throughput with various HTTP/iperf speedtests, just like the specification promised.
Then I enabled UEFI secure boot. And all of my network connections broke 😞. I realized the issue: My DKMS module was not UEFI signed, so the Secure Process would refuse to load it. The OS would still boot, but without the module. Because I had disabled the R8169 module, no network card driver was available.
Obviously I could just have disabled secure boot again, but that would be no fun, would it? Instead, I wanted to get Secure Boot running and keep the R8125B Realtek module. After a bit of googling, it appears that the preferred way of doing this is by employing a so-called Machine-Owner Key (MOK). That is essentially just a certificate + private key that you generate, own, and control. You add that certificate to your UEFI certificate storage, where it will be retrieved by the shim loader. It will then be available to validate kernel modules. Note that this key can by default validate everything, including your own bootloaders, kernels etc. It is possible to limit the MOK to be only valid for kernel module validation (this involves setting a custom OID on the certificate), but doing this is out of scope for this blog post. Our certificate can be used for any purpose, including loading of DKMS modules – if you have signed them with your key.
There are various tutorials out there for various distributions and versions thereof. Here’s what I did – I hope that this is the recommended way, but I’m not entirely sure.
IMPORTANT: If you’re doing this on Debian (like I did), please read Debian’s notes about Secure Boot. It includes compatibility warnings and some pitfalls, such as validation issues in certain cases.
First of all, we need to generate our MOK, meaning a certificate and key. UEFI uses standard X.509 certificates, so if you’re familiar with them this is nothing new:
# Note: This command, and pretty much everything
# else needs to run as root.
openssl req -new -x509 \
-newkey rsa:2048 \
-keyout /root/uefi-secure-boot-mok.key \
-outform DER \
-out /root/uefi-secure-boot-mok.der \
-nodes -days 36500 \
-subj "/CN=Odroid DKMS Signing MOK UEFI Secure Boot"
For those unfamiliar with X.509/OpenSSL, here’s a quick overview: This command generates new RSA private key and corresponding self-signed certificate. We store the key in /root/uefi-secure-boot-mok.key (only accessible as root, important so that no malicious non-root party can use our key) and the certificate in /root/uefi-secure-boot-mok.der. The certificate is valid for 100 years, which isn’t ideal for security, but I am lazy. If you’re paranoid, you might want to lessen the lifetime and rotate your MOK from time to time. You might also want to consider using something else than RSA 2048 keys, but consider that your UEFI loading process must support it. The Subject Common Name (CN) is arbitrary, choose whatever your like.
Next, we need to import that certificate into our UEFI firmware store, where it can be loaded by the shim. Debian and other distributions (like Ubuntu) provide excellent tooling support for this: The Mokutils and MokManager. Basically, we just run this command (as root):
mokutil --import /root/uefi-secure-boot-mok.der
When you run this command, it will ask you for a password. Choose any password, but consider the following:
You will need to type in this password in a short time again. You will only need this password once, it’s a one-time use thing.
You will type in this password in an environment that will likely not use your native keyboard layout, but a default QWERTY one. If possible, choose passwords that you can type even on foreign keyboard layouts.
This does not actually do any real import. What this does instead is it marks this certificate as pending for inclusion for the MokManager. The MokManager is a EFI binary (i.e. a bootable system) included with UEFI-enabled Debian/Ubuntu systems. This is the actual workhorse that will do the import.
We now reboot the system, just use the reboot command or whatever you prefer. Ensure that you have access to a display and keyboard physically connected to your device. After the reboot, you will be presented by the MokManager waiting for you. You probably need to press some key to confirm, otherwise it will just revert to a standard boot. Once you are in the MokManager, just navigate through the options it presents to you. Press “Enroll MOK”, “continue”, “yes”, then enter the password we just setup. The MokManager may use a different keyboard layout! Once that is done and your password is accepted, select OK and wait for the reboot. Your MOK is now installed!
With the MOK installed, the final piece is to sign our DKMS modules with our key. This is very easy with Debian 11 installations, as there’s a ready made helper for this. We just need to edit two files:
Edit /etc/dkms/framework.conf and remove the comment regarding sign_tool:
## Script to sign modules during build, script is called with kernel version
## and module name
sign_tool="/etc/dkms/sign_helper.sh"
We also need to tweak the sign tool slightly, edit this file too and adjust the paths of the certificate and key:
Just use the same filenames and path’s you’ve used while generating the cert + key above. This tutorial uses the same names and paths in all examples for consistency.
Now, we’ve almost done it! DKMS will now sign all modules while they’re build/installed, no additional configuration necessary!
In case you have already installed (unsigned) DKMS modules, we will need to re-build them to ensure they get signed. For my realtek module this involves the following (root again):
dpkg-reconfigure realtek-r8125-dkms
The exact command here varies depending on what modules you have, but the general idea is to call dpkg-reconfigure for each DKMS module you have. DKMS modules itself should be managed by Debian’s “.deb” package system, which is is called dpkg. The Realtek DKMS module is installed by a .deb package called realtek-r8125-dkms, hence the above command will re-install this DKMS module.
Finally, reboot a last time and your modules are now loaded – with UEFI secure boot on!